Overview
GPU infrastructure is significantly more expensive than traditional CPU and memory resources, yet many AI workloads consume only a fraction of the GPU resources allocated to them.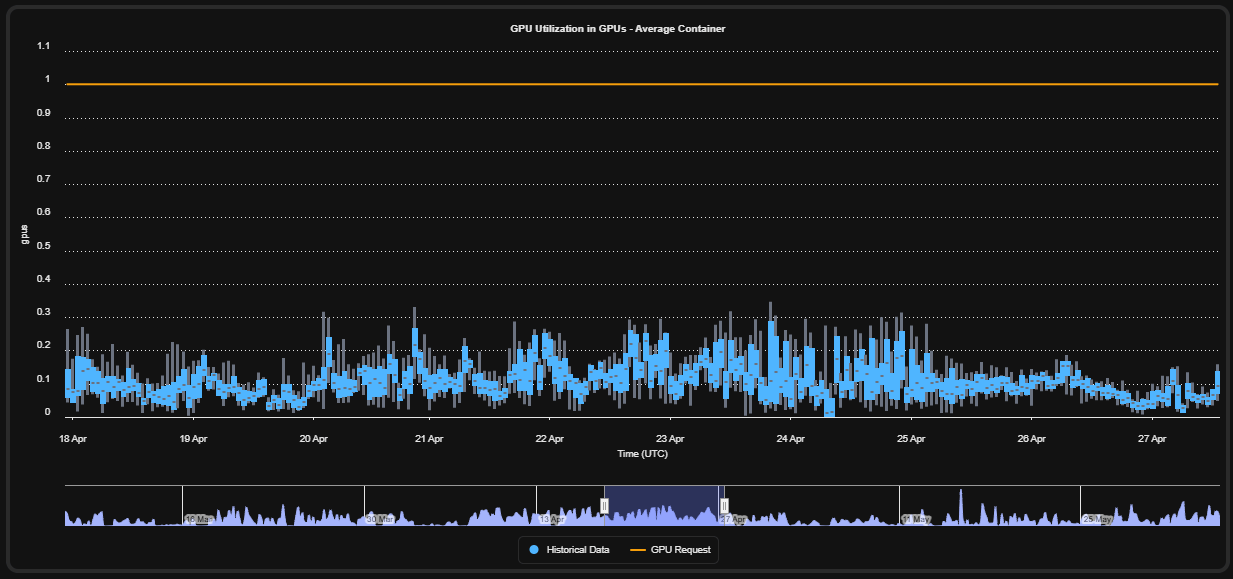
- Continuously monitoring GPU workloads
- Analyzing utilization patterns
- Identifying underutilized GPUs
- Detecting inefficient workload placement
- Recommending workload consolidation strategies
- Optimizing GPU density and infrastructure selection
GPU Workload Visibility
Kubex automatically identifies containers consuming GPU resources and separates GPU spend from standard CPU and memory infrastructure costs. The platform provides:- GPU-specific workload views
- GPU spend analysis
- Per-container GPU allocation visibility
- GPU model identification
- Historical GPU utilization analysis

- Expensive AI workloads
- Inefficient GPU usage
- Oversized GPU allocations
- Unused GPU infrastructure
GPU Utilization Analysis
Kubex continuously analyzes multiple dimensions of GPU consumption.GPU Compute Utilization
Kubex tracks:- Average GPU usage
- Peak GPU consumption
- Sustained utilization
- Real-time GPU demand
- Historical usage trends
- Fully utilizing allocated GPUs
- Underutilizing GPU capacity
- Suitable for consolidation or partitioning
- Workloads averaging 30–50% GPU usage
- Workloads consuming only 10% of a GPU
- Workloads peaking near full GPU capacity
GPU Memory Utilization
Kubex additionally analyzes:- GPU memory allocation
- Memory consumption trends
- Peak GPU memory usage
- Sustained memory utilization
- Consume low GPU compute
- But require large GPU memory footprints
GPU Power Consumption Analysis
Kubex also provides visibility into power usage:- GPU power utilization
- Consumption patterns
- Operational cycles
- GPU efficiency
- Workload intensity
- Resource yield
- Runtime operating behavior
Historical & Pattern-Based Analysis
Kubex performs continuous historical analysis of GPU workloads. The platform evaluates:- Daily operational cycles
- Weekday vs weekend behavior
- Peak activity windows
- Sustained demand periods
- Long-term workload trends
- Temporary spikes
- Stable sustained utilization
- Idle periods
- Predictable usage cycles
GPU Density Optimization
One of Kubex’s core optimization goals is improving GPU density.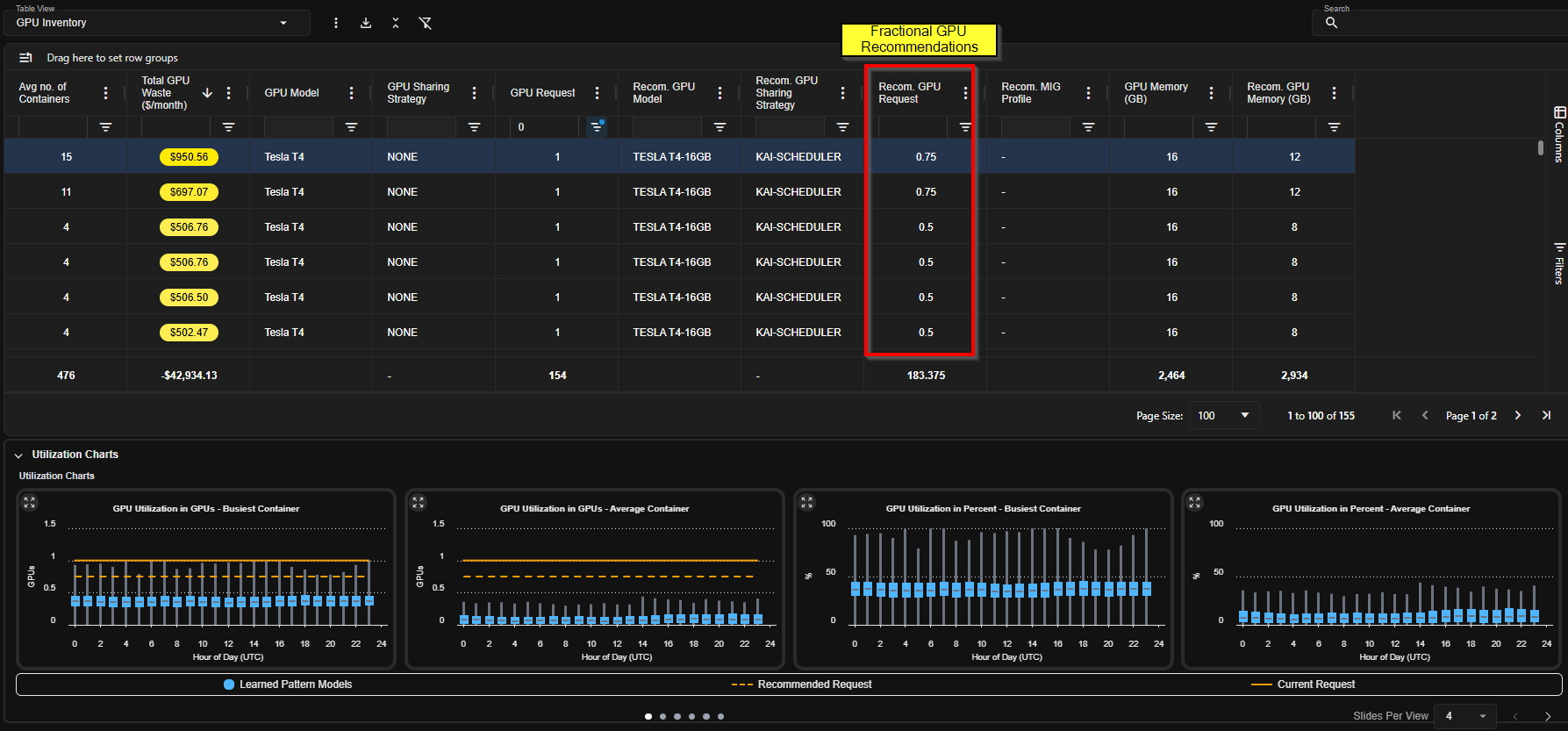
- Use only a fraction of a GPU
- Can safely share GPU resources
- Are candidates for workload consolidation
- Two workloads each consuming ~50% GPU
- Multiple workloads consuming only 10–20% GPU
- Reduce the number of deployed GPUs
- Improve GPU utilization
- Lower infrastructure cost
GPU Partitioning & Sharing Strategies
Kubex evaluates whether workloads can benefit from GPU sharing technologies. Supported optimization strategies include:Multi-Instance GPU (MIG)
For partitionable GPU models, Kubex can identify opportunities to:- Split GPUs into multiple isolated partitions
- Run multiple workloads on a single GPU
- Increase infrastructure efficiency
Fractional GPU Allocation
Kubex can evaluate workloads suitable for:- Shared GPU execution
- Workload multiplexing
- GPU model capabilities
- Workload demand
- Compute requirements
- GPU memory requirements
- Infrastructure cost tradeoffs
GPU Infrastructure Optimization
Kubex evaluates the relationship between workloads and GPU hardware models. The platform can compare:- GPU utilization efficiency
- GPU cost efficiency
- Partitioning capabilities
- Infrastructure suitability
- Stay on lower-cost GPUs
- Migrate to partitionable GPUs
- Consolidate onto newer GPU architectures
- Reduce total deployed GPU count
- Cost
- Performance
- Density
- Response time
- Resource availability
Detection of Unused GPUs
Kubex identifies deployed GPU nodes that are not actively running GPU workloads. These “deadwood” GPUs represent:- Wasted infrastructure cost
- Idle GPU capacity
- Overprovisioned environments
Detection of Non-GPU Workloads on GPU Nodes
Kubex also analyzes workload placement efficiency. The platform detects:- Containers running on GPU nodes
- But not consuming GPU resources
- Node memory
- CPU capacity
- Storage resources
- Higher GPU workload density
- Better cluster efficiency
- Reduced infrastructure waste
Optimization Objectives
Kubex GPU optimization focuses on several key objectives:| Objective | Description |
|---|---|
| Increase GPU Utilization | Improve overall GPU yield |
| Reduce GPU Waste | Eliminate idle or underutilized GPUs |
| Improve Workload Density | Consolidate compatible workloads |
| Optimize Infrastructure Cost | Lower GPU infrastructure spend |
| Improve Placement Efficiency | Ensure GPU nodes host GPU workloads |
| Maintain Performance | Preserve response times and workload behavior |
Business Impact
GPU infrastructure often represents a disproportionate share of Kubernetes infrastructure cost. Kubex commonly identifies opportunities to:- Reduce GPU cost by up to 50%
- Consolidate workloads
- Eliminate idle GPU resources
- Improve utilization efficiency
- Increase AI infrastructure scalability