Cloud Analysis Policy
Cloud Analysis Policies define how Kubex evaluates cloud workloads and generates optimization recommendations. Policies control the analysis window, utilization thresholds, scaling constraints, Kubernetes reservation targets, and instance selection preferences. These settings determine when Kubex recommends:- Upsizing under-provisioned resources
- Downsizing over-provisioned resources
- Terminating unused instances
- Optimizing scale groups
- Adjusting Kubernetes cluster reservations
- Migrating to more efficient instance families or generations
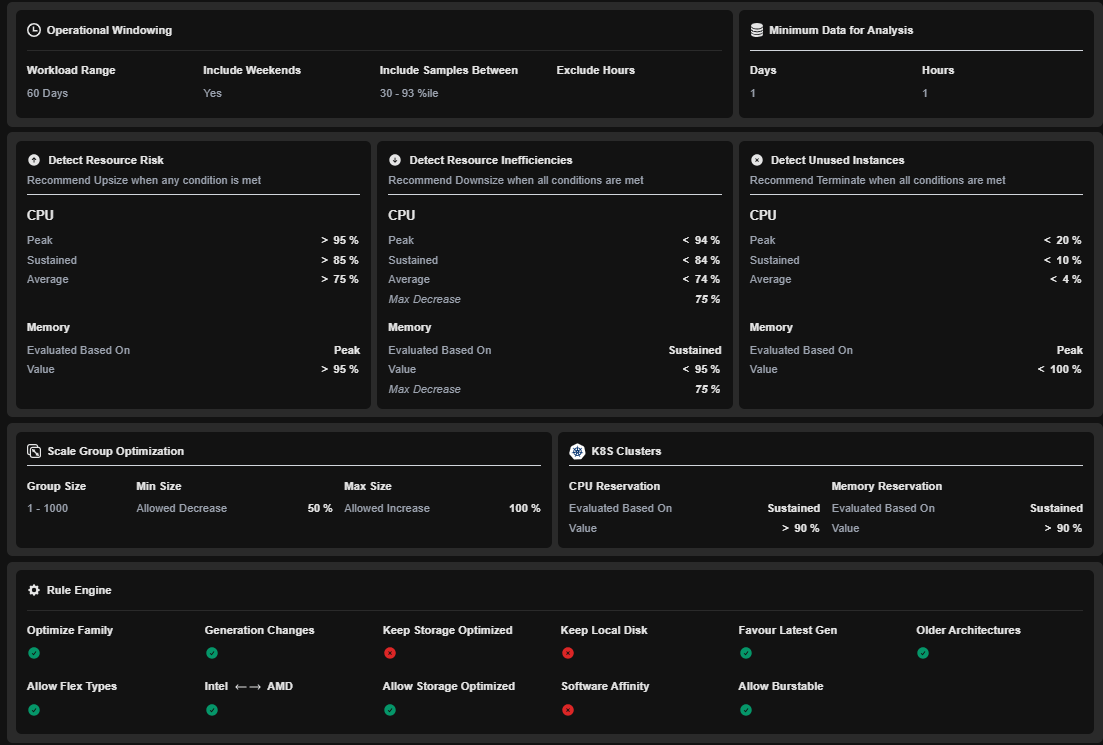
Operational Windowing
The operational window determines which historical utilization data is included during analysis.| Setting | Value |
|---|---|
| Workload Range | 60 Days |
| Include Weekends | Yes |
| Include Samples Between | 0 - 100th Percentile |
| Exclude Hours | None |
| Minimum Data for Analysis | 1 Day / 1 Hour |
Configuration Details
Workload Range
Defines the historical period used for workload analysis. Current Setting:60 Days
A longer analysis period captures seasonal trends and workload variability while reducing sensitivity to short-term spikes.
Include Weekends
Determines whether weekend utilization data is included. Current Setting:Yes
Include Samples Between
Filters utilization samples to eliminate statistical outliers. Default Setting:0 - 100th Percentile
Minimum Data Requirement
| Metric | Value |
|---|---|
| Days | 1 |
| Hours | 1 |
Resource Risk Detection
Resource Risk Detection identifies workloads that may be undersized and at risk of performance degradation. Recommendations are generated when any configured threshold is exceeded.CPU Risk Thresholds
| Metric | Threshold |
|---|---|
| Peak | > 95% |
| Sustained | > 85% |
| Average | > 75% |
Recommendation Logic
Kubex recommends an Upsize when:Memory Risk Thresholds
| Setting | Value |
|---|---|
| Evaluated Based On | Peak |
| Threshold | > 95% |
Recommendation Logic
Kubex recommends an Upsize when:Resource Inefficiency Detection
Resource Inefficiency Detection identifies workloads that are overprovisioned. Recommendations are generated only when all configured conditions are satisfied.CPU Inefficiency Thresholds
| Metric | Threshold |
|---|---|
| Peak | < 94% |
| Sustained | < 84% |
| Average | < 74% |
| Maximum Decrease | 75% |
Recommendation Logic
Kubex recommends a Downsize when:Memory Inefficiency Thresholds
| Setting | Value |
|---|---|
| Evaluated Based On | Sustained |
| Threshold | < 95% |
| Maximum Decrease | 75% |
Recommendation Logic
Kubex evaluates sustained memory utilization and limits reduction recommendations to a maximum 75% decrease.Unused Instance Detection
Unused Instance Detection identifies workloads that can potentially be terminated. Recommendations are generated only when all thresholds are met.CPU Thresholds
| Metric | Threshold |
|---|---|
| Peak | < 20% |
| Sustained | < 10% |
| Average | < 4% |
Memory Thresholds
| Setting | Value |
|---|---|
| Evaluated Based On | Peak |
| Threshold | < 100% |
Recommendation Logic
Kubex recommends a Terminate action when:Scale Group Optimization
Scale Group Optimization controls how Kubex recommends adjustments for Auto Scaling Groups and similar scaling constructs.Configuration
| Setting | Value |
|---|---|
| Group Size | 1 - 1000 |
| Allowed Decrease | 50% |
| Allowed Increase | 100% |
Recommendation Constraints
Kubex will:- Reduce scale groups by at most 50%
- Increase scale groups by at most 100%
- Analyze groups containing between 1 and 1000 instances
Tying Kubernetes Node Groups to the Scale Groups hosting them
When an AWS ASG or Azure ScaleSet hosts an EKS/AKS cluster, scale group optimization cannot rely on utilization metrics alone. Kubernetes CPU and memory requests must also be included in the analysis. If Kubex is connected to the Kubernetes clusters, it can correlate scale groups with their node groups and produce actionable recommendations.CPU Request
| Setting | Value |
|---|---|
| Evaluated Based On | Sustained |
| Threshold | > 90% |
Memory Request
| Setting | Value |
|---|---|
| Evaluated Based On | Sustained |
| Threshold | > 90% |
Rule Engine
The Rule Engine controls how Kubex selects target instance types during optimization.| Rule | Description |
|---|---|
| Optimize Family | Allow alternative instance families when a more cost-effective or performant option exists |
| Generation Changes | Permits migration between instance generations |
| Favor Latest Generation | Prioritizes newer generation instance types when available |
| Older Architectures | Allow recommendations to older CPU architectures |
| Allow Flex Types | Permits recommendations to flexible instance families where supported |
| Intel ↔ AMD Migration | Allows cross-architecture recommendations between Intel and AMD platforms when cost or performance benefits exist |
| Allow Storage Optimized | Enables recommendations to storage-optimized instance types when appropriate |
| Allow Burstable | Allows migration to burstable instance families for suitable workloads |
| Keep Storage Optimized | Stay on a storage optimized instance |
| Keep Local Disk | Kubex is allowed to recommend instance types without local storage |
| Software Affinity | Recommendations are not constrained by software-specific affinity requirements |
Recommendation Summary
With this policy configuration:- Workloads at risk are upsized when CPU or memory utilization exceeds defined thresholds.
- Overprovisioned workloads are downsized based on CPU and memory efficiency rules.
- Nearly idle workloads are flagged for termination.
- Scale groups can shrink by up to 50% or grow by up to 100%.
- Instance recommendations can migrate across families, generations, and CPU vendors to maximize efficiency and cost savings.